게으른 블로거라서 죄송합니다..!
자주 쓰려고 노력하고 있지만, 쉽지만은 않습니다 ㅜㅜ
오늘 소개드리려고 하는 포스팅과 내용은 Music 분야의 deeplearning 입니다.
딥러닝의 발전이 빠르다는 것은 이제는 입아픈 말이지요.
그럼에도 불구하고 이 포스팅의 저자는 음악 분야는 아직 쉽지않다고 얘기합니다.
왜 그렇게 생각하는지 같이 들어볼까요?
오늘은 미리 제 의견을 말씀드려볼게요!
포스팅에 제시된 이유로 음악 AI가 불가능하다는 내용 보다는,
앞으로 음악 분야의 AI에서 해결되어야 하는 난제들이 있다는 것을 느꼈습니다.
그리고 이런 어려움을 해결할 수 있는 역량있는 엔지니어가 아주 귀하다는 것도요!
(포스팅 원문 : ally12.medium.com/why-are-there-so-few-music-related-ai-projects-f74cf866f6af )
-----------------------------------------------------------------------
구글의 Magenta 프로젝트를 제외하고는 Music ai 분야가 그렇게 발전하지는 않았습니다.
(cv nlp와 같은 분야에 상대적으로?)
음악분야 AI의 경험과 클래식 음악의 경험을 바탕으로 제 생각을 말씀드려 볼게요.
첫째로 음악을 코딩하는게 너무 어렵습니다.
단기간에 익힐 수 있는 것도 아니구요.
spectrogram을 비교하는 고급 신호 처리 및 딥러닝에 대해 알아야 하고
모델을 적용하기 전에 많은 데이터 조작(전처리)이 필요합니다.
컴퓨터가 소리와 주파수를 바로 분석할 수 없기 때문에 음성 ai에서는 빠지지않고 스펙트로그램이 쓰입니다.
스펙트로그램 그래프는 시간과 주파수에 따라 비교하고 색상을 사용하여 특정 주파수에서 신호의 강도를 표시합니다.
오디오 파일에서 이런 스펙트로그램을 만드는 것은 캐글에서 클릭만으로 데이터셋을 다운받는 것보다 훨씬 어렵습니다.
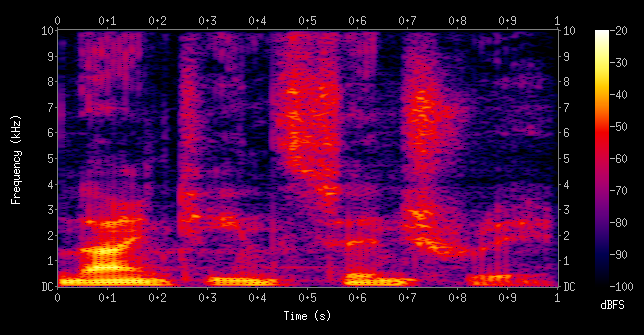
먼저 사운드 파일을 연산할 수 있도록 WAV파일로 변환해줘야 합니다.
그 다음에 bit rate와 모델에서 사용할 size와 같도록 맞춰줘야 합니다.
(저는 이걸 모르고 24bit WAV파일을 8, 16, 32 bit를 요구하는 모델에 넣는 실수를 했습니다)
아니면 bit rate을 직접 정하는 방법도 있긴 합니다(개발하면서 깨달아야 합니다).
그 다음에는 그래프 작성을 위해 오디오 데이터를 준비해야 합니다.
데이터를 준비하는 과정에는 고속 푸리에 변환을 이용해서 주파수를 분리하는 과정도 있고,
Melody scale을 이용하여 사람이 인지할 수 있는 소리를 분류하는 과정,
특정 주파수를 강조하고 데이터를 만지는 등 여러 작업들이 포함됩니다.
이 과정을 통해 소리를 그래프로 표현할 수 있습니다.
그리고 이렇게 해서 나온 spectrogram을 array로 만들고 레이블링 해주는 것까지 해야합니다.
Royal Melboreune Institute of Technology의 Haytham Fayek의 블로그에서
머신러닝을 위한 음성 신호처리를 조금 더 알아볼 수 있습니다.
haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between
Understanding and computing filter banks and MFCCs and a discussion on why are filter banks becoming increasingly popular.
haythamfayek.com
음성 데이터를 다루기 위해서는 신호 처리 분야에 대한 전문적인 지식과
미적분 및 선형대수에 대한 지식이 필요합니다.
(푸리에 변환, 해밍 윈도우와 같은 개념들이 되겠지요)
이를 바탕으로 스펙트로그램이나 음성기반 이미지를 만들어 낼 수 있습니다.
이걸 딥러닝에 적용하는 것은 그나마 쉽지만 여전히 많은 어려움이 있습니다.
음악은 여전히 미묘한 요소가 많아서 스펙트로그램만으로 파악할 수 없습니다.
머신러닝 알고리즘은 Tempo, Volume, Tone, Expression, Articulation과 같은
음악적인 요소를 어떻게 설명하나요?
사람은 그냥 시끄러운 소리와 일부러 만들어 낸 큰 소리를 구분할 수 있지만
컴퓨터에게는 쉽지 않습니다.
프로 뮤지션이나 구분할 수 있는 미묘한 따뜻한 소리와 차가운 소리를 컴퓨터는 구분하기 힘듭니다(지금은).
머신러닝 알고리즘이 음악의 시각적인 연출, 뮤지션과 청중의 관계와 감정을 이해할 수 있나요?

오케스트라와 같이 여러 세션이있는 작품에서도 아직 딥러닝의 한계가 있습니다.
프로젝트를 설계하면서 음악을 치환해주는 기존 서비스에 대해 조사했습니다.
Chordify가 인기를 끌고 있지만 악기는 피아노, 기타, 우쿨렐레로 제한됩니다.
합주하는 부분의 음악만을 기록하죠.
반면에 인간은 여러 악기파트의 8마디를 나눠서 들을 수 있고 각 부분을 재생할 수 있습니다.
Chordify는 사전에 녹음된 파일만 가져오는 아쉬움도 있습니다.
형평성과 다양성 문제도 있을 수 있습니다.
이번 포스팅에서 서양 클래식 음악을 예시로 설명했는데요,
12톤 시스템을 사용하지 않는 다른 문화의 음악(인도음악 등)을 다룰 때에는 또 어떻게 될까요?
음악 장르마다 특징이 다르기 때문에 한 장르에 훈련된 모델은 다른 장르를 분석하지 못합니다.
결정적으로, 음악관련 딥러닝을 만드는 것은 시간을 효율적으로 들일 수 없습니다.
Grammarly for music(음악을 분석해서 피드백을 제공하는 툴) 같은 도구는 코딩하는 데에
엄청난 양의 리소스를 필요로합니다.
이런 음악 툴의 개발자는 음악과 개발, 두 가지 분야에 대한 전문지식이 필요합니다.
두 분야 모두 집중적인 수년의 훈련기간이 소요됩니다.
이런 이유들 때문에, 저는 음악 분야의 AI가 music generation에 한정되어 있다고 생각합니다.
이번 포스팅에서 자세히 설명드리지는 않겠습니다만,
컴퓨터에게는 음악을 그냥 재생하는 것이 분석하는 것보다 훨씬 쉽습니다.
오늘 포스팅의 요점은 이겁니다.
NLP와는 다르게 음악 분야는 당분간은 AI의 발전으로부터 안전하다는 것입니다.
20년 쯤 뒤에는 지금의 제 말이 틀릴겁니다.
하지만 아직은 음악 AI는 여러 난제가 있습니다.
그러니까 뮤지션들은 악기를 내려놓지 마세요!
------------------------------------------------------------------
간단요약
1. 음악을 코딩하는 것이 아직 많이 어렵다
2. 다양한 장르와 스타일의 음악들을 컴퓨터가 분석하기도 쉽지 않다
3. 수학, 프로그래밍, 음악분야 지식 모두를 갖춘 엔지니어가 귀하다!
'AI_Column' 카테고리의 다른 글
| AI는 지금 되풀이되는 위기를 겪고 있습니다 (6) | 2020.11.15 |
|---|---|
| AI의 창의성(Creativity)에 대한 박지은 펄스나인 대표의 칼럼입니다 (1) | 2019.11.23 |
| 논문 읽기와 ML/DL 커리어 경력에 대한 조언 by 앤드류 응 (21) | 2019.08.22 |


